






In the data-driven world of SEO, we navigate vast oceans of URLs, keywords, log files, and analytics data daily. Efficiently filtering, analyzing, and manipulating this information isn’t just helpful—it’s essential for success. But what if you had a secret weapon to perform these tasks with surgical precision? Enter Regex, or Regular Expressions.
If “Regex” sounds like complex coder territory, you’re not alone. Many SEOs feel intimidated. However, understanding even the basics of Regex can dramatically elevate your SEO capabilities, saving countless hours and revealing insights hidden within your data.
This comprehensive guide demystifies Regex for SEO professionals. We’ll explore what it is, why it’s a crucial skill, and most importantly, how to apply it effectively in everyday tools like Google Analytics, Google Search Console and SEO crawlers
What Exactly is Regex?
Regex is a sequence of characters that defines a search pattern. It allows you to match, extract, or manipulate text with precision. Instead of just searching for a fixed word like blog, Regex allows you to search for patterns like:
- Any URL path starting with /blog/
- Any search query containing exactly three words
- Any line in a log file ending with .pdf
- Any keyword that is phrased as a question (starting with “what”, “how”, etc.)
- All URLs containing a specific parameter, regardless of its value
Essentially, Regex is a powerful mini-language designed specifically for pattern matching within text. It allows you to define flexible search criteria that go far beyond simple keyword lookups, enabling the discovery of insights that might not be apparent through conventional methods.
Why Should SEOs Bother Learning Regex? The SEO Advantage
Learning Regex isn’t about becoming a programmer; it’s about becoming a more efficient, insightful, and data-driven SEO. Here’s why it’s worth your time:
- Precision Filtering & Deeper Insights: Stop manually sifting through endless rows. Regex enables highly specific filters in Google Analytics (GA4), Google Search Console (GSC), and SEO crawlers (Screaming Frog). Isolate exactly the data you need—specific URL structures, branded vs. non-branded queries, pages with certain parameters, question-based keywords—uncovering trends hidden by broad filters.
- Efficiency & Time Savings: Automate repetitive tasks. Categorizing large keyword lists, cleaning up URL data, finding specific code snippets (like tracking pixels or schema) across thousands of pages, or extracting specific data points becomes significantly faster.
- Advanced Analysis & Technical SEO: For technical SEO, Regex is invaluable. Analyze log files for bot behavior, write complex .htaccess redirect rules, perform large-scale content audits, identify indexation issues, and conduct sophisticated competitive analysis by identifying competitor patterns.
- Improved Data Accuracy: Extract and manipulate data with greater precision, ensuring the information you rely on for decision-making is exactly what you need.
- Better Crawl Budget Optimization: Use Regex in crawlers or server logs to identify and potentially exclude irrelevant or low-value URLs (e.g., faceted navigation parameters, duplicate content), guiding search engine bots to your most important pages more effectively.
- Enhanced Reporting: Create more meaningful reports in tools like Looker Studio by using calculated fields with Regex functions to segment data in ways not possible with standard filters.
Decoding Regex: The Building Blocks
You don’t need to memorize the entire Regex dictionary. Understanding these core “metacharacters” (special characters with meaning) and concepts will get you surprisingly far:
Core Metacharacters:
| Sr. No. | Character | Name | Meaning | Use Case | Example Regex | Matches |
|---|---|---|---|---|---|---|
| 1 | . | Dot / Wildcard | Matches any single character (except newline) | Finding variations (e.g., seo vs séo) | b.t | bat, bet, b@t |
| 2 | * | Asterisk / Star | Matches the preceding character 0 or more times | Matching optional directories or parameters | /blog.* | /blog/, /blog/post, /blog/new |
| 3 | + | Plus | Matches the preceding character 1 or more times | Ensuring at least one subdirectory exists | /blog/.+ | /blog/post, but not /blog/ |
| 4 | ? | Question Mark | Matches the preceding character 0 or 1 time | Handling optional trailing slashes or 's' | https? / folder/? | http, https / folder, folder/ |
| 5 | ^ | Caret / Hat | Matches the beginning of the string | Filtering URLs starting with a specific path | ^/products/ | /products/item, but not /blog/products/ |
| 6 | $ | Dollar | Matches the end of the string | Finding URLs ending with a specific extension | \.pdf$ | document.pdf, but not document.pdf?v=1 |
| 7 | | | Pipe | Pipe / Vertical Bar | Acts as an OR operator | Matching multiple brand variations or categories | blog|blogpost |
| 8 | [] | Square Brackets | Matches any single character within the brackets | Matching specific numbers or letter ranges | /[1-5]00/ / gr[ae]y | /100/ to /500/ / gray or grey |
| 9 | () | Parentheses | Groups characters together; creates capture groups | Grouping for OR logic or extracting specific parts | `^(blog | news)/` |
| 10 | \ | Backslash | Escapes a metacharacter (treats it literally) | Matching a literal dot, question mark, etc. | \.com / \? | The literal .com / The literal ? |
Important Concepts & Shorthands:
- Escaping: Remember to use \ before special characters (., ?, *, +, (, ), [, ^, $, |) if you want to match the literal character. For example, to match example.com, you need example\.com.
- Character Sets: [a-z] (any lowercase letter), [A-Z] (any uppercase), [0-9] (any digit). Combine them like [a-zA-Z0-9].
- Shorthand Character Classes:
- \d: Matches any digit ([0-9]). Example: product-\d{4} matches product-1234
- \w: Matches any “word” character (letters, numbers, underscore: [a-zA-Z0-9_]). Example: \w+-seo-\w+
- \s: Matches any whitespace character (space, tab, newline). Example: seo\s+tips matches seo tips with one or more spaces.
- \S: Matches any non-whitespace character.
- Quantifiers: Specify how many times something should match (used after a character or group):
- {n}: Exactly n times. \d{3} matches exactly 3 digits.
- {n,}: n or more times. \d{4,} matches 4 or more digits.
- {n,m}: Between n and m times. \w{5,10} matches 5 to 10 word characters.
- Anchors: ^ (start) and $ (end) are crucial for ensuring your pattern matches the entire string/URL path/query, not just a part of it.
- Greedy vs. Lazy Matching: By default, * and + are “greedy” (match as much as possible). Adding a ? after them makes them “lazy” (match as little as possible). Example: <p>.*</p> might match across multiple paragraphs. <p>.*?</p> is often better for matching just one.
Pro-Tip: Tools often have options like “Matches regex,” “Contains regex,” “Full match,” etc. Pay attention to these settings, as they influence whether ^ and $ are implicitly used or needed.
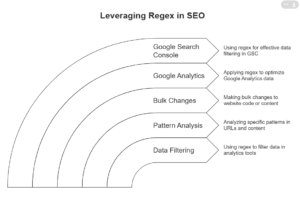
Regex in Action: Practical SEO Use Cases Across Platforms
Let’s see how Regex shines in your daily workflow:
- Google Analytics (GA4 )
- Filtering Reports:
- Exclude Internal IPs: (Requires specific IP patterns, often involving escaping dots: ^192\.168\.1\.\d{1,3}$)
- View Blog Traffic Only: ^/blog/.* (Page path dimension)
- Isolate Product Pages with Numeric IDs: ^/products/\d+$
- Filter Out Specific URL Parameters: example-page\?utm_source=.* (Use negative match) or filter for pages without certain parameters ^(?!.*\?utm_source=) (requires Lookahead knowledge – more advanced).
- Combine Sections: ^/(blog|resources|case-studies)/.*
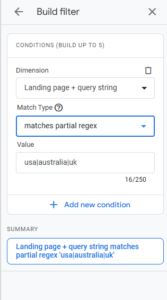
- Creating Segments/Audiences (GA4):
- Users Visiting Any Service Page: Dimension Page path and screen class, Matches regex ^/services/.*
- Users Landing on Pages Without Trailing Slashes: Matches regex ^/[^/]+/[^/]+$ (Example for depth 2, adjust as needed)
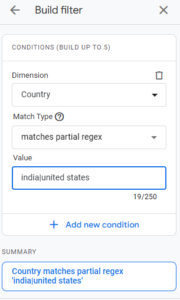
- Goal/Conversion Setup (UA/Some GA4 Events):
- Match Multiple Thank You Page Variations: ^/thank-you(-confirmation|-order)?$
Example (GA4 Filter): Show only traffic to blog posts OR news articles.
- Dimension: Page path and screen class
- Match Type: Matches regex
- Expression: ^/(blog|news)/.*
- Google Search Console (GSC)
- Filtering Queries:
- Brand vs. Non-Brand: (Assuming brand is “facebook”)
- Brand: Query -> Custom (regex) -> facebook?|fb (Case insensitive often default, check tool)
- Non-Brand: Query -> Doesn’t match regex -> facebook?|fb
- Question Keywords: Query -> Custom (regex) -> ^(who|what|when|where|why|how|is|are|can|do|does)\s
- Long-Tail Keywords (e.g., 5+ words): Query -> Custom (regex) -> ^\s*(\S+\s+){4,}\S*\s*$ (Matches queries with at least 4 spaces, implying 5+ words)
- Specific Topics/Intent: Query -> Custom (regex) -> compare|vs|review|best|top
- Find Misspellings: Query -> Custom (regex) -> widg?ets?|gadg?ets? (If common misspellings are known)
- Brand vs. Non-Brand: (Assuming brand is “facebook”)
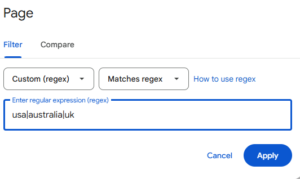
- Filtering Pages:
- Specific Sections: Page -> Custom (regex) -> ^https://www\.yourdomain\.com/category/.*
- URLs with Parameters: Page -> Custom (regex) -> \? (Finds any URL with a question mark)
- Exclude Parameter URLs: Page -> Doesn’t match regex -> \?
- AMP Pages: Page -> Custom (regex) -> /amp/$
- Find Non-HTTPS URLs: Page -> Custom (regex) -> ^http://
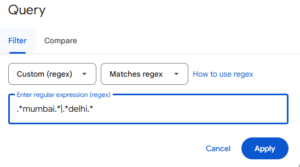
Example (GSC Query Filter): Find queries containing “compare” OR “vs”.
- Filter Type: Query
- Condition: Custom (regex)
- Regex: compare|vs
- Looker Studio
In Looker Studio, regular expressions (regex) are powerful tools for manipulating and analyzing text data.
They allow you to define patterns to search, match, extract, or replace portions of strings within your data
In Looker Studio, regular expressions (regex) are powerful tools for manipulating and analyzing text data. They allow you to define patterns to search, match, extract, or replace portions of strings within your data. Here’s a breakdown of how regex is used in Looker Studio:
Key Regex Functions in Looker Studio:
Looker Studio provides several functions that utilize regular expressions:
- REGEXP_EXTRACT:
- This function extracts the first substring that matches a given regex pattern.
- It’s useful for pulling specific pieces of information from a text field.
- REGEXP_MATCH:
- This function returns TRUE if the entire input string matches the regex pattern, and FALSE otherwise.
- It’s helpful for filtering or creating boolean dimensions based on pattern matching.
- REGEXP_CONTAINS:
- This function returns TRUE if the input string contains any substring that matches the regex pattern, and FALSE otherwise.
- This is very useful for finding if a certain pattern exists anywhere inside of a text string.
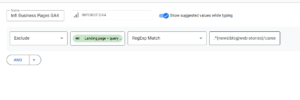
Where Regex is Used:
- Calculated Fields:
- You can use regex functions within calculated fields to create new dimensions or metrics based on pattern matching.
- Filters:
- Regex can be used in filters to include or exclude data based on complex string patterns.
- Data Cleaning:
- Regex is essential for cleaning up inconsistent or messy data, such as standardizing URL formats or extracting specific information from text fields
- SEO Crawlers (Screaming Frog, Sitebulb, etc.)
- Include/Exclude URLs:
- Crawl Only Blog Subdomain: Include ^https?://blog\.yourdomain\.com.*
- Exclude Parameterized URLs: Exclude .*\?.*
- Exclude Specific File Types: Exclude \.(pdf|jpg|png)$
- Custom Extraction (Incredibly Powerful!): Extract data directly from page HTML/source code.
- Find Pages Missing GA Code: Mode Regex, Extractor Does Not Contain, Regex UA-\d{4,}-\d{1,}|G-[A-Z0-9]{10} (Adjust for your specific ID patterns)
- Extract All Email Addresses: [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
- Extract H1 Tags: <h1[^>]*>(.*?)</h1> (Extracts content between tags)
- Extract Canonical URLs: <link\s+rel=[“‘]canonical[“‘]\s+href=[“‘](.*?)[“‘]
- Check for Specific Schema Type: “@type”:\s*”Product”
- Extract Phone Numbers: (Complex, varies by format) (\+?\d{1,3}[-.\s]?)?\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4} (Basic US-style, adapt globally)
Example (Screaming Frog Custom Extraction): Find H1 content.
- Mode: Regex
- Extractor: Extract
- Regex: <h1[^>]*>(.*?)</h1>
Getting Started & Navigating Challenges
Regex can seem complex, but you can master it progressively:
- Start Simple: Focus on the core metacharacters first: . * + ? ^ $ | [] () \.
- Pick One Tool: Master Regex filters in GSC or GA4 before exploring crawlers or spreadsheets.
- Use Online Regex Testers: Crucial! Websites like Regex101.com or RegExr.com are invaluable. Paste your data (URLs, queries), type your pattern, and see live matches highlighted. They often provide explanations of your pattern too.
- Break It Down: If a pattern is complex, analyze each part (^, (group), [set], *, $) separately.
- Copy, Paste, Modify: Find existing Regex patterns online for common SEO tasks (like the examples above) and adapt them carefully to your specific domain, structure, or needs.
- Practice: Apply Regex to small, real-world tasks frequently. Categorize 20 keywords, filter 50 URLs. The more you use it, the more intuitive it becomes.
- Be Aware of Syntax Variations: Regex implementation can differ slightly between tools (e.g., GSC). Test within the specific tool you are using.
- Beware of Errors & Over/Under-Matching: A small mistake in a pattern (like a missing \ escape or a greedy .*) can lead to incorrect data. Test thoroughly on sample data before applying to critical tasks or large datasets. Aim for precision.
- Leverage AI (Carefully): Tools like ChatGPT can help generate Regex patterns from natural language prompts (“Create Regex to find URLs starting with /blog/ but not ending with /feed/”). Always test AI-generated Regex thoroughly, as it may not be perfectly accurate or optimal.
Conclusion: Master Regex, Master Your SEO Data
Regular Expressions might appear daunting initially, but they are an incredibly potent tool in any serious SEO’s arsenal. By learning fundamental principles and practicing their application, you can:
- Filter data with unparalleled precision.
- Uncover deeper insights from analytics, search performance, and crawl data.
- Automate time-consuming, repetitive tasks.
- Perform advanced technical analysis and audits more effectively.